25 million Creative Commons image dataset released#
Fondant is an open-source project that aims to simplify and speed up large-scale data processing by making containerized components reusable across pipelines & execution environments, shared within the community.
A current challenge for generative AI is compliance with copyright laws. For this reason, Fondant has developed a data-processing pipeline to create a 500-million dataset of Creative Commons images to train a latent diffusion image generation model that respects copyright. Today, as a first step, we are releasing a 25-million sample dataset and invite the open source community to collaborate on further refinement steps.
Fondant offers tools to download, explore and process the data. The current example pipeline includes a component for downloading the urls and one for downloading the images.
Creating custom pipelines for specific purposes requires different building blocks. Fondant pipelines can mix reusable components and custom components.
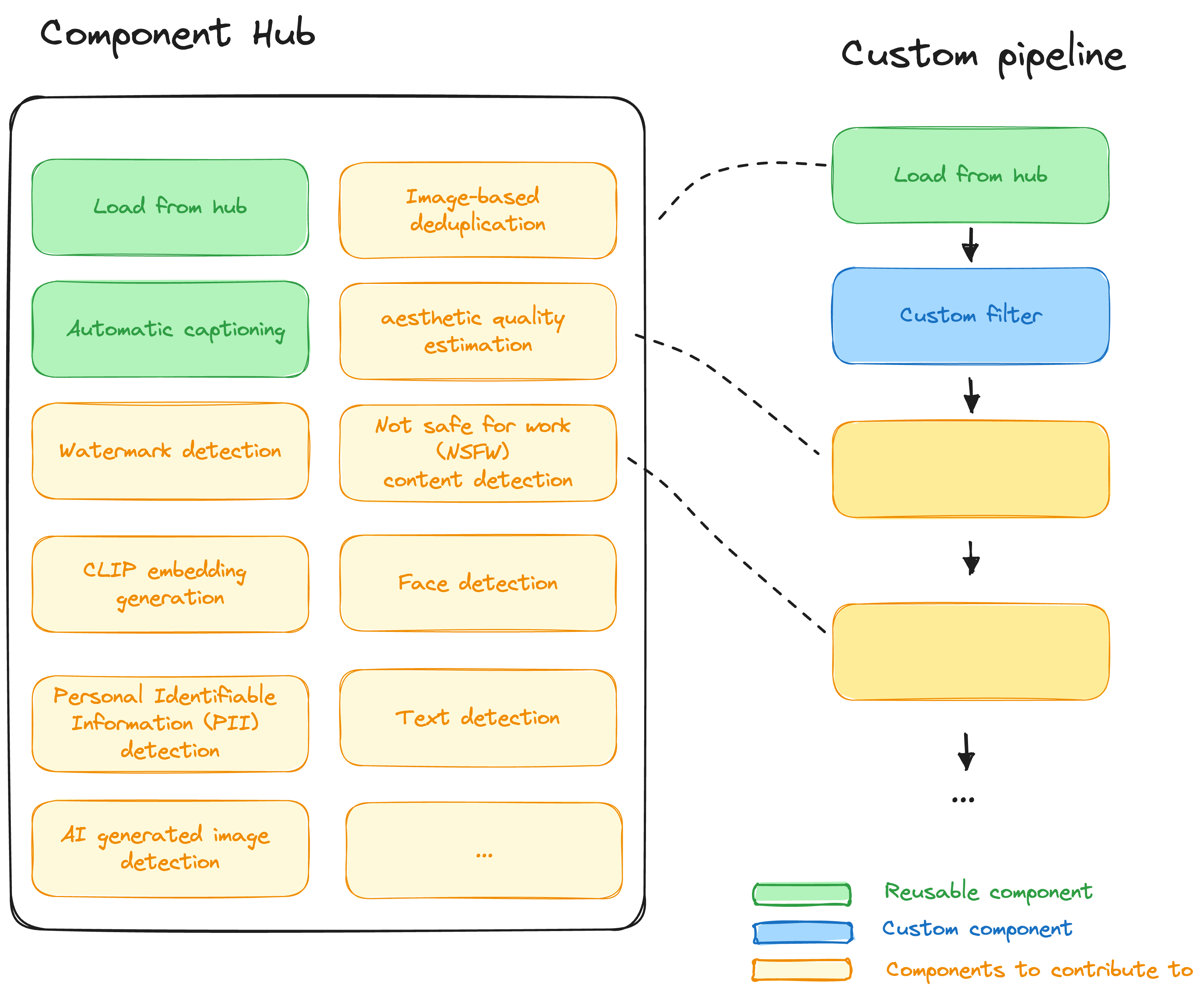
Additional processing components which could be contributed include, in order of priority:
- Image-based deduplication
- Visual quality / aesthetic quality estimation
- Watermark detection
- Not safe for work (NSFW) content detection
- Face detection
- Personal Identifiable Information (PII) detection
- Text detection
- AI generated image detection
- Any components that you propose to develop
The Fondant team also invites contributors to the core framework and is looking for feedback on the framework’s usability and for suggestions for improvement. Contact us at info@fondant.ai and/or join our discord.