Building your own dataset#
This guide will teach you how to build and run your own datasets using components available on the Fondant Hub.
Overview#
In this guide, we will build a dataset workflow that downloads images from the fondant-cc-25m dataset and filters them.
It consists of three steps:
- load_from_hf_hub: Loads the dataset containing image urls from the Huggingface hub.
- download_images: Downloads images from the image urls.
- filter_language: Filters the images based on the alt text language
Setting up the environment#
We will be using the local runner to materialize the dataset. To set up your local environment, please refer to our installation documentation.
Building the dataset#
We initialize a dataset using the Dataset.create() method. This method creates a new dataset using
Fondant components. Components are executable elements of a workflow that consume and produce data.
You can use two types of components with Fondant:
- Reusable components: A bunch of reusable components are available on our hub, which you can easily add to your dataset.
- Custom components: You can also implement your own custom component.
If you want to learn more about components, you can check out the components documentation.
1. A reusable load component#
As a first step, we want to read data into our dataset. In this case, we will load a dataset from the HuggingFace Hub. For this, we can use the reusable load_from_hf_hub component.
We can create a dataset by using the Dataset.create() method, which returns a (lazy)
Dataset.
We create a file called dataset.py and add the following code:
from fondant.dataset import Dataset
dataset = Dataset.create(
"load_from_hf_hub",
dataset_name="creative_commons_pipline",
arguments={
"dataset_name": "fondant-ai/fondant-cc-25m",
"n_rows_to_load": 100,
},
produces={
"alt_text": pa.string(),
"image_url": pa.string(),
"license_location": pa.string(),
"license_type": pa.string(),
"webpage_url": pa.string(),
}
)
View a detailed reference of the options accepted by the Dataset class
We provide three arguments to the .create() method:
- The name of the reusable component
- The name of the dataset
- Some arguments to configure the component. Check the component's documentation for the supported arguments
- The schema of the data the component will produce. This is necessary for this specific
component since the output is dynamic based on the dataset being loaded. You can see this
defined in the component documentation with
additionalProperties: trueunder the produces section.
View a detailed reference of the Dataset.create() method
Read data using the provided component.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
ref |
Any
|
The name of a reusable component, or the path to the directory containing a containerized component, or a lightweight component class. |
required |
produces |
Optional[Dict[str, Union[str, DataType]]]
|
A mapping to update the fields produced by the operation as defined in the component spec. The keys are the names of the fields to be received by the component, while the values are the type of the field, or the name of the field to map from the dataset. |
None
|
arguments |
Optional[Dict[str, Any]]
|
A dictionary containing the argument name and value for the operation. |
None
|
input_partition_rows |
Optional[Union[int, str]]
|
The number of rows to load per partition. Set to override the |
None
|
resources |
Optional[Resources]
|
The resources to assign to the operation. |
None
|
cache |
Optional[bool]
|
Set to False to disable caching, True by default. |
True
|
dataset_name |
Optional[str]
|
The name of the dataset. |
None
|
Returns:
| Type | Description |
|---|---|
Dataset
|
An intermediate dataset. |
#
To materialize your dataset, you can execute the following command within the directory:
The workflow execution will start, initiating the download of the dataset from HuggingFace. After the workflow has completed, you can explore the dataset using the fondant explorer:
You can open your browser at localhost:8501 to explore the loaded data.
2. A reusable transform component#
Our dataset contains the dataset from HuggingFace. One of these columns,
url, directs us to the original source of the images. To access and utilise these images
directly, we must download each of them.
Downloading images is a common requirement across various use cases, which is why Fondant provides a reusable component specifically for this purpose. This component is appropriately named download_images.
We can add this component to our dataset as follows:
Looking at the component documentation, we can see that
it expects an "image_url" field, which was generated by our previous component. This means
that we can simply chain the components as-is.
3. A reusable transform component with non-matching fields#
This won't always be the case though. We now want to filter our dataset for images that contain
English alt text. For this, we leverage the
filter_language component. Looking at the component
documentation, we can see that it expects an "text"
field, while we would like to apply it to the "alt_text" field in our dataset.
We can easily achieve this using the consumes argument, which lets us maps the fields that the
component will consume. Here we indicate that the component should read the "alt_text" field
instead of the "text" field.
english_images = images.apply(
"filter_language",
arguments={
"language": "en"
},
consumes={
"text": "alt_text"
}
)
View a detailed reference of the Dataset.apply() method
Apply the provided component on the dataset.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
ref |
Any
|
The name of a reusable component, or the path to the directory containing a custom component, or a lightweight component class. |
required |
workspace |
workspace to operate in |
required | |
consumes |
Optional[Dict[str, Union[str, DataType]]]
|
A mapping to update the fields consumed by the operation as defined in the component spec. The keys are the names of the fields to be received by the component, while the values are the type of the field, or the name of the field to map from the input dataset. Suppose we have a component spec that expects the following fields: To override the default mapping and specify that the 'text' field should be sourced from the 'custom_text' field in the input dataset, the 'consumes' mapping can be defined as follows: In this example, the 'text' field will be sourced from 'custom_text' and 'image' will be sourced from the 'image' field by default, since it's not specified in the custom mapping. |
None
|
produces |
Optional[Dict[str, Union[str, DataType]]]
|
A mapping to update the fields produced by the operation as defined in the component spec. The keys are the names of the fields to be produced by the component, while the values are the type of the field, or the name that should be used to write the field to the output dataset. Suppose we have a component spec that expects the following fields: To customize the field names and types during the production step, the 'produces' mapping can be defined as follows: In this example, the 'text' field will retain as text since it is not specified in the custom mapping. The 'width' field will be stored with the name 'custom_width' in the output dataset. Alternatively, the produces defines the data type of the output data. In this example, the 'text' field will retain its type 'string' without specifying a
different source, while the 'width' field will be produced as type |
None
|
arguments |
Optional[Dict[str, Any]]
|
A dictionary containing the argument name and value for the operation. |
None
|
input_partition_rows |
Optional[Union[int, str]]
|
The number of rows to load per partition. Set to override the |
None
|
resources |
Optional[Resources]
|
The resources to assign to the operation. |
None
|
cache |
Optional[bool]
|
Set to False to disable caching, True by default. |
True
|
Returns:
| Type | Description |
|---|---|
Dataset
|
An intermediate dataset. |
#
Inspecting your data#
Now, you can proceed to execute your workflow once more and explore the results. In the explorer, you will be able to view the images that have been downloaded.
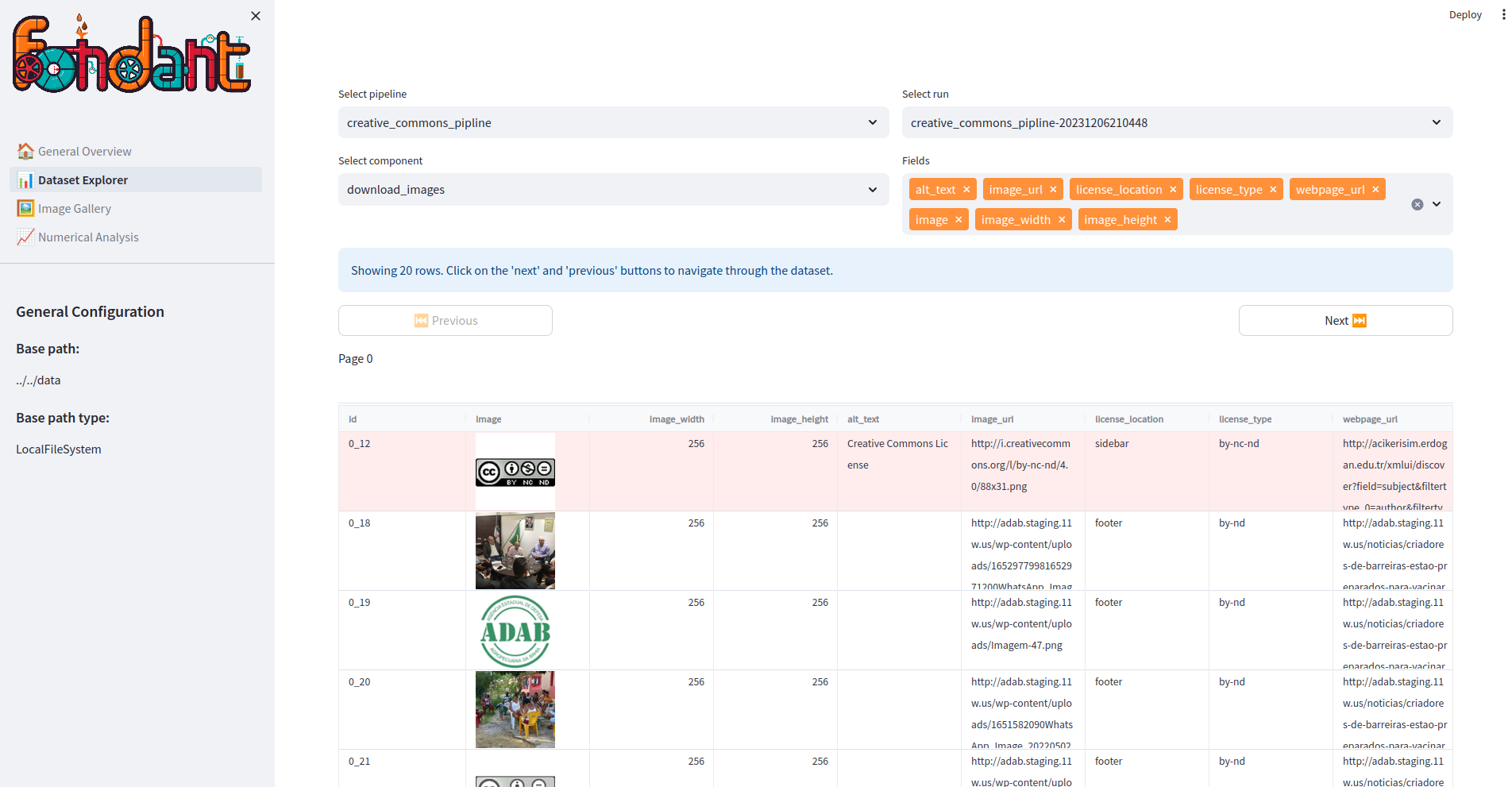
Export the dataset#
If you want to inspect your final dataset without using the data explorer or use the
dataset for further tasks, we recommend to write the final dataset to a destination.
We offer write components to perform this task, for instance the write_to_file component,
which allows you to export the dataset either to a local file or a remote storage bucket.
You can open the path and use any tools of your choice to inspect the resulting Parquet dataset.
Well done! You have now acquired the skills to construct a simple Fondant dataset by leveraging reusable components. In the next tutorial, we'll demonstrate how you can customise the dataset by implementing a custom component.